Optimizing our CSS at Glean


Back when Glean first started, we chose to use inline styles. This did not scale well as we grew, so we decided to survey CSS-in-JS options. vanilla-extract, our chosen solution, optimizes performance (zero-runtime overhead) and developer experience at the cost of a slightly steeper learning curve.
Read this if you:
- Want to learn about performance and developer experience tradeoffs between common, modern CSS frameworks
- Are interested in trying out zero-runtime CSS-in-JS solutions
{{richtext-banner-component}}
Our survey of CSS framework options
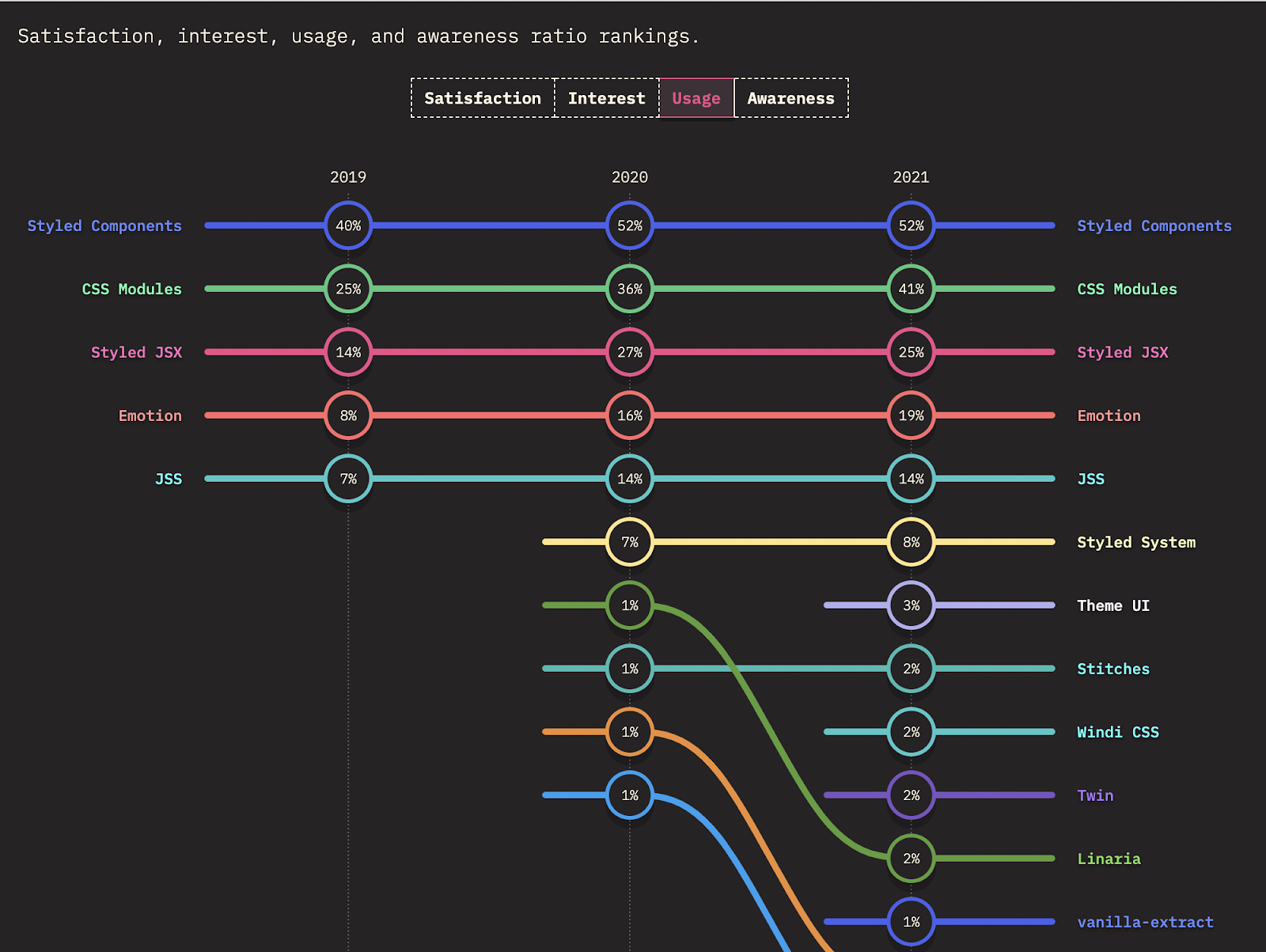
We started our search for a CSS solution by checking trends and surveys such as State of CSS (2021). From usage below, we saw that Styled Components and CSS Modules were a close-ish #1 and #2. Note that vanilla-extract’s usage was near the bottom, at 1%. This made sense given its first stable release was in May 2021.
However, from developer satisfaction, we saw that vanilla-extract was leading, and CSS Modules was a very close second.
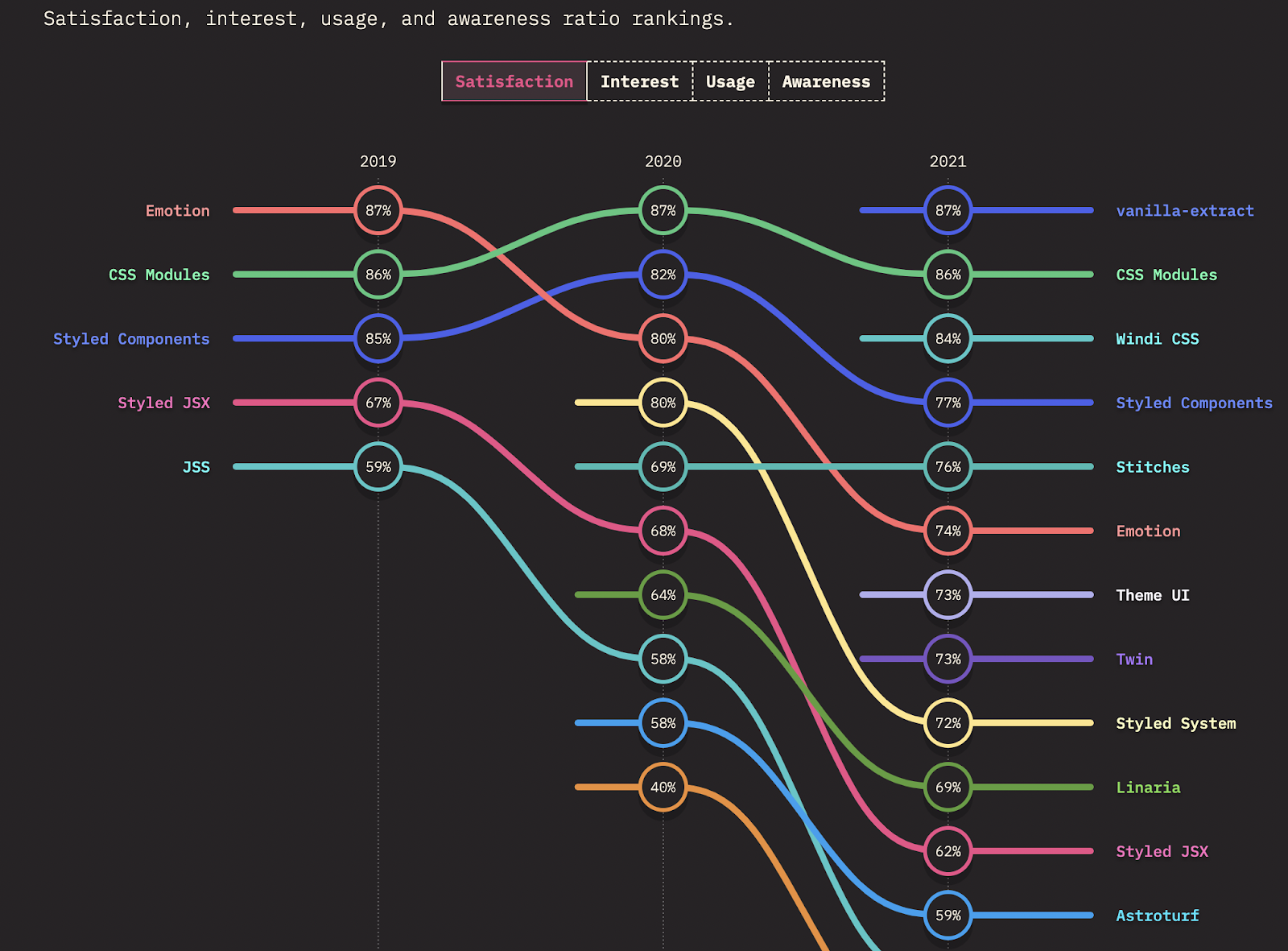
To tiebreak our 3 leading options of Styled Components, CSS Modules, and vanilla-extract, we read developer blogs to dig into the pros/cons.
Why we ruled out Styled Components
Styled Components are an opinionated mechanism of packing style properties (unclassed) into a React Component. Our main concern with Styled Components was its runtime overhead. We didn’t run a Styled Components prototype, but other developers’ notes were convincing. In short, Styled Components incurs a runtime bundlesize overhead from its loader. Its render, like inline styles, is also blocked until JS execution.
CSS Modules were promising
CSS Modules are a mechanism of obfuscating CSS classes to hack local scoping into CSS. We liked its philosophical separation of concerns between CSS files and React Component files. Furthermore, CSS Modules transpile down to plain CSS assets, which are:
- More parallelizable: CSS only blocks render (not parse) whereas JS blocks HTML parsing.
- Faster for the browser to apply: See the JS styling overhead in this benchmark.
However, CSS Modules are not a CSS-in-JS solution, and would require migrating from TS to CSS or a preprocessor.
Why we chose vanilla-extract
vanilla-extract’s pitch as a best of both worlds (CSS-in-JS and CSS Modules) solution was promising enough to prototype. Recall vanilla-extract is a build time TS to CSS modules preprocessor. It’s also worth noting that vanilla-extract’s author is the co-creator of CSS Modules, which is second to Styled Components in current usage.
We suspect that Styled Components has high usage but relatively lower satisfaction because it’s easy for smaller-to-medium sized projects to start up (no CSS preprocessor). Whereas CSS Modules and vanilla-extract are a better fit for larger projects due to their performance, file layout, and debuggability benefits.
vanilla-extract vs. CSS Modules
CSS Modules and vanilla-extract both support zero-runtime overhead. That is, transpiled native CSS lets the browser do what it does best in native code rather than running in JS "user space" which parses much more slowly and gets blocked during load.
However, we believe vanilla-extract’s CSS-in-JS approach is better than CSS Module transpilation because TS integration offers IDE intellisense, Webpack bundle splitting, tree shaking (dead code pruning), etc. In short: easier refactoring, and better web performance due to minimal asset size.
That said, our reservations about adopting vanilla-extract still hold true. We’ve adopted the project fairly early. For example, Facebook’s CSS-in-JS solution, Stylex, might open source and become more popular. This concern is somewhat mitigated by Stylex’s similarity. Both transpile TS down to CSS Modules. If push comes to shove, swapping similar solutions might not be terrible. Lastly, from the linked article, Stylex should have been released in late 2021, but is still not available as of Sep 2022. This may be a signal that Stylex is conceding to vanilla-extract’s open source traction. We measure traction by: increasing adoption measured by npm downloads, and Github commits.
Migrating from inline styles to vanilla-extract
While we had switched to vanilla-extract for new features, we still had to migrate the existing inline styles in the codebase. This also turned out to be a fairly large refactor, as we had over ~300 files (10K lines of code) to convert to vanilla-extract.
Manually migrating some of the stylesheets we noticed that the effort is fairly mechanical as we’re converting one style of code to another; So we decided to write a codemod to do some heavy lifting.
Refactoring using codemods
A codemod is a set of transformations to automate changes that would essentially comprise a refactor. The idea is to treat the code as data for another program that would be able to understand its structure and apply specific transforms. Given the right setup, codemods can reduce a ton of time and effort that goes into large scale refactors.
Looking into the implementation, our codemod scripts would do the following for each stylesheet:
Step 1. Convert inline style rules to vanilla-extract styles
For each file we had to convert style rules into corresponding vanilla-extract style() declarations. We do use a custom Stylesheet() declaration for our existing inline styles, which is a good starting point for the codemod script. At a high level we’re looking at four separate transformations:
- Find all Stylesheet() declarations in the file.
- For each Stylesheet(), extract each property and expression to create a new variable declaration.
For eg: `container: { …styleRules }` → `export const container = style({ ...styleRules })` - Add an import for `style` from vanilla-extract.
- Remove the Stylesheet() declaration and import.
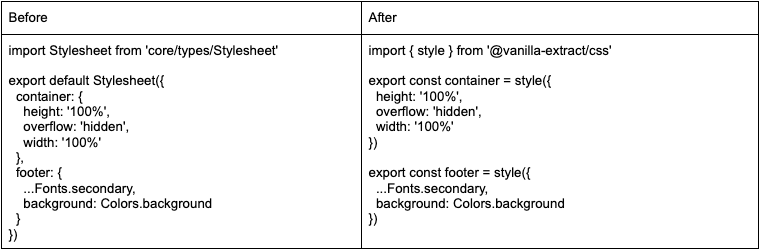
Step 2. Finally, update ‘style’ props to ‘className’ in the JSX components
With the styles transformed, we also had to convert the components that were using these inline styles.
Locating them was straightforward as most of our components share a naming convention with their styles.
Once the files are located, we’re looking at a few more transformations:
- Convert style JSXAttributes to className and reference the transformed styles.
- Update the default styles import to named imports since we have moved away from a default Stylesheet export above.
Step 3. Add .css.ts to the filename
At this point, both the stylesheet and the component has been transformed, so the only thing left is to rename the file and add .css.ts to the filename.
Tools
We used ASTExplorer to explore and visualize the Abstract syntax tree (AST) for the code and figure out where to apply transformations. We also used JSCodeshift which provides a neat API to apply transformations to the code.
Vanilla extract in practice
After prototyping, and widely adopting, we realized classNames for debugging was our greatest productivity improvement. The React Component tree and DOM tree often differ greatly. A className=$fileName_$elementClass_$moduleHash (ex: ProfilePage_mainPersonCard__1bmv6no1) is far more debuggable than hacking around inline styles’ lack of sourcemaps. For example, we previously hotloaded tracer textNodes each time we needed to map rendered styles to TS source:
<div style={{...inlineStylesToDebug}}> {/* no sourcemaps */}
Test: is this the div I’m debugging? {/* tracer textNode */}
<SomeComponent />
</div>
The costs of adopting vanilla-extract were one-time:
- There’s a learning curve to adopting classNames. Ex: arbitrary className specificity resolution. Developers needed to learn new practices such as preferring a max of 1 className per DOM element:
// Near-equivalent of SCSS mixins
const deepMergedClassName = style([baseStyle, otherBase, componentOverrides])
- Initial migration bugs. Migrating from inline styles to classNames breaks when selectors tie, and when previously common !important properties are present. Manually detecting bugs was tedious, but the bugs motivated more automated Storybook screenshot diff tests, which prevent future regressions
Takeaways
Some of the benefits of working at a fast-growing startup are:
- There’s no lack of impactful work when there’s a lot of low-hanging fruit.
- If you spot an improvement, you can often fully own solutions.
If building or using a best-in-class search product sounds interesting to you, reach out!
Related articles

What is Retrieval Augmented Generation (RAG)?
